I came across an interesting problem on the website of UofT prof David Liu (who I had the privilege of TAing for a few years back). Part of what makes the problem amusing—I think—is how we respond to it.
Consider the following Python program:
def has_even(A):
for i in range(len(A)):
if A[i] % 2 == 0:
return i
return -1
Suppose we’re running it on the domain of binary strings of length 
Dave’s solution is rigorous—he’s trying to instil good practices in his students—but if, like me, you haven’t done this in a while, it’s helpful to take a more primitive tack.
We’ve got 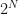

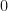
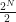
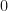

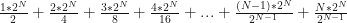
(The final term is an annoying edge-case: the string that is all 
![\frac{1}{2^{N}} * [\frac{1 * 2^{N}}{2} + \frac{2 * 2^{N}}{4} + \frac{3 * 2^{N}}{8} + ... + \frac{(N-1) * 2^{N}}{2^{N-1}} + \frac{N * 2^{N}}{2^{N-1}}] = \frac{1}{2} + \frac{2}{4} + \frac{3}{8} + ... + \frac{(N-1)}{2^{N-1}} + \frac{N}{2^{N-1}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%5E%7BN%7D%7D+%2A+%5B%5Cfrac%7B1+%2A+2%5E%7BN%7D%7D%7B2%7D+%2B+%5Cfrac%7B2+%2A+2%5E%7BN%7D%7D%7B4%7D+%2B+%5Cfrac%7B3+%2A+2%5E%7BN%7D%7D%7B8%7D+%2B+...+%2B+%5Cfrac%7B%28N-1%29+%2A+2%5E%7BN%7D%7D%7B2%5E%7BN-1%7D%7D+%2B+%5Cfrac%7BN+%2A+2%5E%7BN%7D%7D%7B2%5E%7BN-1%7D%7D%5D+%3D%C2%A0%5Cfrac%7B1%7D%7B2%7D+%2B+%5Cfrac%7B2%7D%7B4%7D+%2B+%5Cfrac%7B3%7D%7B8%7D+%2B+...+%2B+%5Cfrac%7B%28N-1%29%7D%7B2%5E%7BN-1%7D%7D+%2B+%5Cfrac%7BN%7D%7B2%5E%7BN-1%7D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
The first and final terms are both bounded by

We might remember from our analysis class that no matter the size of 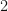
By parallel reasoning, the same holds if we take our domain to be arrays of uniformly distributed random integers. You can vary the modulus in the function, and the offset is given by the appropriate geometric series. If, like me, you’ve been ruined by a career in engineering and you prefer simulations to real math, here you go:

Until I worked through the problem it wasn’t at all clear to me what the answer was, and I was a little surprised when I finally arrived at 
It’s well-documented that people don’t naturally think in terms of probabilities. Scientists have literally won Nobel prizes for demonstrating this. If you don’t believe me you can read them; alternatively you can spend an afternoon at your local offtrack parlor. The gravity of an event warps our perception of its likelihood. We fret over worst-case-scenarios—no matter how unlikely they are—because they stick out in our mind. We buy lottery tickets for a similar reason. We regard winning the 649 as a “life-altering” event, not as a “hopelessly improbable” one. This is sometimes called probability neglect.
When I looked at the problem, I thought of the strings that consist entirely of
