Suppose we hypothesize that louder background noises make people more irritable (shout out to the kid who sat next to me on the flight last week — you’re driving scientific progress). To test our hypothesis, let’s conduct an experiment.
- Subjects sit for two minutes in the presence of a humming sound
- For members of Group A, the sound is played at 20 decibels
- For members of Group B, the sound is played at 40 decibels
- Subjects then rate their irritability on a scale of 1 to 10.
(This example is taken from Howard J. Seltman’s Experimental Design and Analysis.) Suppose that the median control score is 3.0 and the median treatment score is 6.0. We can conclude that increasing background noise increases irritability, right?
Well, maybe. Here’s what Seltman says:
If you want to convert that to meaningful statements about the effects of auditory environmental disturbances on the psychological trait or construct called “irritability”, you must be able to argue that the scales have good construct validity for the traits, namely that the operationalization of background noise as an electronic hum has good construct validity for auditory environmental disturbances, and that your irritability scale really measures what people call irritability.
We can’t directly observe “irritability.” It’s a theoretical construct. To understand it, we have to triangulate from more concrete measures, such heart rate, pupil size, or self-reported irritability scores. Construct validity is about assessing how well our quantitative measures and higher level theoretical constructs all fit together.
The audience of this blog (hi Mom!) consists of data scientists at tech companies, who at this point might be thinking “who fucking cares?” — to which I’d respond “basically everyone.” For the past five years tech companies have been embroiled in scandal, and more often that not it has to do with externalities caused by algorithms chasing a narrowly defined goal. For a while we were all deluded into believing that we can directly optimize for the “correct” objective — be it clickthrough, revenue, or whatever — without any regard for made-up bullshit that can’t be objectively measured. You know, like “happiness,” or “trust.” It’s a convenient perspective if you’re the product manager for a recommender system, but it’s obviously wrong. Higher-level psychological constructs have proven unavoidable in social science, and there’s no good reason our discipline should be any different. Statisticians, economists, and mathematical psychologists have spent decades grappling with questions that are “new” to data science, and there is much to be learned from their work.
The notion of construct validity was introduced to the psychology literature in the mid 1950s, when the committee on psychological tests discussed it in a report on recommendations for tests and diagnoses. The following year, Lee Cronbach and Paul Meehl published a paper exclusively devoted to the topic entitled “Construct Validity in Psychological Tests.” Anyone who is even mildly interested in social science will have encountered questions of construct validity – “Does IQ actually measure what we call intelligence?”, “Are self-reported happiness scores meaningful? And if so, can we compare them across languages?” But it’s worth developing a language for addressing them precisely. Cronbach and Meehl write:
Construct validity calls for no new scientific approach. Much current research on tests of personality is construct validation, usually without the benefit of a clear formulation of the process.
A clear formulation will allow us to catch ourselves when we’re failing to perform construct validation, and it will provide us with a toolbox of techniques for effective analysis. Like his collaborator Daniel Kahneman, Meehl’s talent lies in his ability to look at the familiar with a fresh eye. The paper is a goldmine of insights for how to think about data. It’s divided into three parts: an intro, a list of techniques, and a discussion of philosophical underpinnings. For our purposes, the most interesting claims are made in the second section. Six techniques for assessing construct validity are considered. Two are mostly criticized.
- Group differences: “If our understanding of a construct leads us to expect two groups to differ on the test, this expectation may be tested directly.” The example they give is a test about religious attitudes that was validated by comparing church goers’ responses to non churchgoers’ responses. They point out that the correlation shouldn’t be perfect, as this would suggest that you might be testing the wrong thing: “an intelligence test that correlates .95 with age in an elementary school sample would surely be suspect.”
-
Factor Analysis: The ML/NLP crowd will recognize this as SVD-based techniques, such as latent semantic analysis. Social scientists have been doing this for years. Cronbach and Meehl are justifiably skeptical:
Factors may or may not be weighted with surplus meaning. Certainly when they are regarded as ‘real dimensions’ a great deal of surplus meaning is implied, and the interpreter must shoulder a substantial burden of proof.
I find it totally implausible that dimensionality reduction of some survey data would give you the “real dimensions” or mood/attention/etc. I think this is even less plausible than the already dubious claim that LSA gives you the “dimensions of meaning.”
- Studies of internal structure: This refers to the intercorrelations of quantities related to some higher level trait. They don’t say much about this, other than that it is worth sanity checking. But as we’ll see, internal structure became a recurring theme in attempts to quantify construct validity.
-
Studies of change over occasions: This is more subtle than just replicability. Here’s a quote I love:
More powerful than the retest after uncontrolled intervening experiences is the retest with experimental intervention. If a transient influence swings test scores over a wide range, there are definite limits on the extent to which a test can be interpreted as reflecting the typical behaviour of the individual.
Examples include changing the wording of questions and changing the interviewer.
- Studies of process: a model of how a subject completes a task might reveal that our test measures more than the target attribute. They cite this study as an example.
-
Numerical estimates: Simply put, the authors are pessimistic about this.
In the following years a lot of people worked on defining numerical estimates of construct validity. I don’t think this work has yielded a silver bullet, and by the nature of the problem it never will. But it has provided a few new tools to throw at the problem. There are two papers worth mentioning.
An important first stab at providing a numerical estimate of construct validity was published four years later by Donald Campbell and Donald Fiske. They advocate examining properties of a multitrait-multimethod matrix. In their setup, you have a few different traits each measured by a few different techniques. You lay out the correlations between measures in a matrix. Here’s their synthetic example:
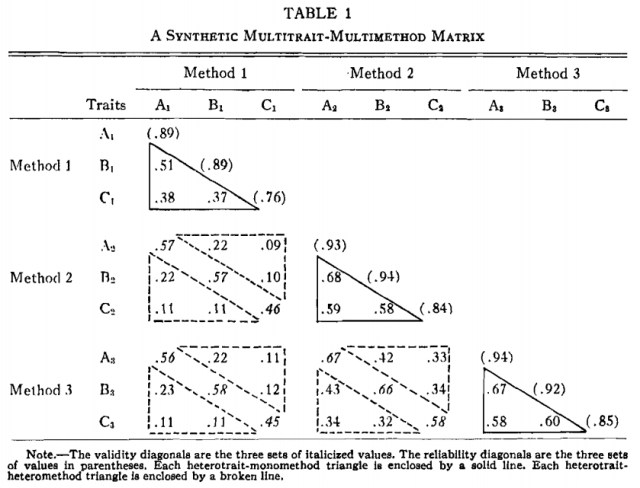
For instance, the entry in the fourth row, first column (the value is .57) gives the correlation of the measurements of Trait A using Method 1 and the measurements of Trait A using Method 2. The diagonals of the sub-matrices are singled out as “validity diagonals” because they indicate the agreement of the respective methods on each trait. The diagonal of the entire matrix contains the reliability estimates of each test. Campbell and Fiske claim there are four things we want to see in this matrix.
- Entries in the diagonal should be significant (these are the reliability estimates of each test — if they are near zero we’re sunk).
-
Each entry in a validity diagonal should exceed the values in its row/column in the submatrix. Basically this is saying that Method X and Method Y should correlate more on trait A than, say, Method X’s value for Trait A correlates with Method Y’s value for Trait B. If they don’t, these numbers start to look arbitrary. The example satisfies this criterion.
-
Each entry in a validity diagonal should exceed the values in the solid triangles (called heterotrait-monomehod triangles). This is saying a measurement should “correlate higher with an independent effort to measure the same trait than with measures designed to get at other traits which happen to employ the same method.” If we fail this test, we’re learning more about our tools than our subjects.
-
The triangles should exhibit the same pattern. This means that we’ve found the same “pattern of trait interrelationship.” In other words, if trait A correlates better with trait B than trait C under some method, the same should hold under any other method.
The authors then apply their technique to a number of important datasets. They observe that even the first two criteria (which aren’t particularly strong) don’t always hold.
A more recent example of a numerical estimate of construct validity was given by Drew Westen and Robert Rosenthal in a 2003 paper. They suggest two simple coefficients that are predicated on similar concepts to those discussed in the work from the 50s. The one I want to discuss is ralerting-CV. Suppose we have some quantitative measure m and we want to assess it’s validity for measuring some high-level construct C. We take the set of other measures associated with C, and we make predictions for how m correlates with each of these. Then we see how our predictions correlate with the actual correlations. The resulting coefficient is ralerting-CV.
The motivation here is that we are testing our understanding of how our measures interlock. If we can make reasonably good predictions, it suggests that we have a clear picture of the network we’re trying to fill out. If we can’t, it suggests that we know what the nodes are but not the edges.
Suppose we operate a video-sharing app. We have recently become CCPA compliant, and we are running an A/B test in which we share this fact in the feed of the treatment group. We want our response variable to estimate the degree to which our users trust us with their data. Historically we have measured this by whether or not they have shared a video on our platform, but we’ve become frustrated with this measure, because on average it takes people a while to post something.
We are considering using whether or not they have denied a device permission instead. It will give us our answer faster, because users are typically asked to grant device permissions early in the adoption cycle. But before we start using this measure we want to assess its validity for the trust construct.
Some other measures that we believe are (less directly) related to trust are whether they have verified their account, whether they have ever shared a video via another platform (Facebook, Twitter, etc), and whether they have logged on with more than one device.
Let’s pretend that in reality, our app has two types of users: “consumers,” who are primarily interested in viewing content, and “creators,” who are primarily interested in posting it. Naturally the creators are more likely to post a video. They’re also more tech-savvy, and consequently more likely to deny device permissions. They almost invariably verify their accounts, so that they can get royalties for successful content. By contrast, the consumers almost never bother to verify. Creators don’t share a lot — they only share their own posts for marketing. Consumers share lots of posts on social. For simplicity we’ll assume these are represented as bernoulli-distributed binary attributes. Here’s a synthetic dataset:
from __future__ import division
from numpy.random import binomial
from numpy import hstack, vstack
consumers = hstack((
binomial(1, 0.9, (500000, 1)), # all permissions allowed
binomial(1, 0.5, (500000, 1)), # posted a video
binomial(1, 0.2, (500000, 1)), # verified account
binomial(1, 0.8, (500000, 1)), # shared a post
binomial(1, 0.1, (500000, 1)), # more than one device
))
creators = hstack((
binomial(1, 0.3, (500000, 1)), # all permissions allowed
binomial(1, 1.0, (500000, 1)), # posted a video
binomial(1, 1.0, (500000, 1)), # verified account
binomial(1, 0.6, (500000, 1)), # shared a post
binomial(1, 0.6, (500000, 1)), # more than one device
))
users = vstack((consumers, creators))
In making a successful ralerting-CV estimate, the magnitude of our estimates is less important than the relative ordering. We need to figure out that the best correlate for allowing permissions is sharing a post – these are both “consumer” behaviours. Posting a video and using multiple devices are tied for second. Verification is the worst, as typically only creators bother to do this.
from scipy.stats import pearsonr
pearsonr(
(
pearsonr(users[:,0], users[:,1])[0],
pearsonr(users[:,0], users[:,2])[0],
pearsonr(users[:,0], users[:,3])[0],
pearsonr(users[:,0], users[:,4])[0],
),
(
0.2,
0.0,
0.6,
0.2,
)
)
(0.9939805796340004, 0.006019420365999563)
I think that figuring this out apriori would be very, very difficult. Supposing that we are allowed to examine all columns of the user matrix except the first one (as that would give away the answer), it’s not obvious to me that any technique that doesn’t lean heavily on domain knowledge would get you there.
Here’s a somewhat contrived recipe for estimating a good ralerting-CV on this problem:
- cluster the data into two groups
- you will find that one group (the creators, though we don’t know them as such) has more average activity than the other group
- assume that the group with less average activity (the consumers) has a propensity to accepting permissions
- make your estimates by measuring the correlation of these group members with the other trust attributes
from sklearn.cluster import KMeans
model = KMeans(n_clusters=2)
preds = np.argmax(model.fit_transform(users[:, 1:4]), axis=1)
group_0 = np.mean(np.sum(users[:, 1:4][preds==0], axis=1))
group_1 = np.mean(np.sum(users[:, 1:4][preds==1], axis=1))
pearsonr(
(
pearsonr(users[:,0], users[:,1])[0],
pearsonr(users[:,0], users[:,2])[0],
pearsonr(users[:,0], users[:,3])[0],
pearsonr(users[:,0], users[:,4])[0],
),
(
pearsonr([preds, 1-preds][group_0 < group_1], users[:,1])[0],
pearsonr([preds, 1-preds][group_0 < group_1], users[:,2])[0],
pearsonr([preds, 1-preds][group_0 < group_1], users[:,3])[0],
pearsonr([preds, 1-preds][group_0 < group_1], users[:,4])[0],
)
)
(0.9603455622423943, 0.039654437757605694)
Hopefully this code snippet was met with total incredulity. In the first place, how do you know there are two natural user groups? Had we had tried to tune k using the elbow method, the scores would max out at 23 (the data is discreet). And secondly, even if you know a-priori that there were two groups, how do you determine how they correlate with device permission denial? Answers to these questions require domain-expertise about the process by which the data was generated, rather than a Kaggle-like approach where we start optimizing without asking what the column names are.
I don’t really have a final word or punchline here; this post is more questions than answers. I will say that if you’re interested, reading Meehl is probably a good place to start.
Further reading
Construct Validity in Psychological Tests
Cronbach and Meehl, 1955
Convergent and discriminant validation by the multitrait-multimethod matrix
Campbell and Fiske, 1959
What is Construct Validity?
James Dean Brown, 2000
Quantifying Construct Validity: Two Simple Measures
Westen and Rosenthal, 2003
Experimental Design and Analysis
Howard J. Seltman, 2018
